資料倉儲的重要技術議題
如同其他系統一般,要導入資料倉儲之前要非常了解用戶的需求,但除此之外,使用資料倉儲有兩個非常重要的技術議題要考量:「資料擴張」以及「資料轉入」問題。「資料擴張」問題來自於資料由RDB(Relational Database)轉為MDDB(Multi-Dimensional Database)過程會進行預儲及預算,因此會耗用大量的空間儲存資料;而「資料轉入」問題則來自傳統交易系統普遍有資料不一致、資料衝突狀況,當有許多交易系統要同時轉入一個資料倉儲時,這個問題就會變得非常嚴重。
你能想像1Giga的RDB資料轉為MDDB後變為100Giga的情況?如果RDB轉為MDDB時,RDB本身就是「垃圾進、垃圾出」,所作出來的MDDB資訊有用嗎?這篇文章將為您探討這些問題,並看看業界用何種解決方案處理。
當RDB變為MDDB時的資料擴張狀況
這是一個非常嚴肅但又很少人會去注意的問題,如果你在業界真的要去進行資料倉儲方案的開發,假設你有1Giga的RDB資料(在連鎖零售業,一個月就會有超過一Giga的銷售資料,或是500Mega的訂購資料),有20個Dimension要分析,你絕對想像不到當資料變為MDDB時,由於經過預算與預儲,可能會變成上百Giga甚至上千Giga的窘境,你的硬碟將會爆掉,你也會發現你買硬碟或其它儲存裝置的錢比起你買資料倉儲軟體的錢還要來得多!
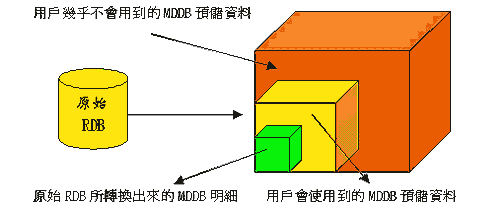
RDB資料變為MDDB資料時之所以會產生的大量資料擴張,主要是由於預儲的關係。為了追求更好的處理績效,一般OLAP軟體都會利用預算與預儲的方式,事先將用戶可能查詢的彙總結果進行運算並加以儲存,因此資料倉儲會比一般的資料庫得大,如(圖一)是一般資料倉儲資料的組成,包括原始的RDB轉為MDDB的原始明細資料、用戶真正會用到的預儲資料,以及為了那些天馬行空、不可知的用戶需求而產生的預儲資料。原始的資料只佔了MDDB很小的比例,可是隨著分析維度變多,那些天馬行空的資料所佔的空間就會不斷的變大。
這種資料擴張的狀況是可以理解的,不過由於受到下列四個因素的影響,MDDB的資料擴張似乎在業界都還沒有被最佳化的處理:
● 資料倉儲軟體對於稀疏資料的處理不當:假設你有二十筆銷售資料,分別屬於A、B、C、D、E、F、G、H、I、J等十種商品的銷售類別資料,其中A、B、E、F、G、H類別是完全沒有資料,當我們以商品與門市建立二維的MDDB時,在正常情況下A、B、E、F、G、F應該是不會與任何的門市產生彙總式資料的,可是,大部份的軟體在進行前置性的預算與預儲時,卻是會為其保留空間,但這些空間事實上是沒有資料的!當這種資料稀疏狀況非常嚴重、而要分析的維度又很多時,這種空間浪費就會是一個很嚴重的問題
● 多維式資料儲存策略未臻完善:在資料儲存策略方面,一般可以分別依用戶狀況將資料儲存在MOLAP(查詢最快,但最耗空間)、ROLAP(查詢最慢,但最省空間)或HOLAP(介於MOLAP與ROLAP之間),這三種策略都是一種直覺式的策略,也就是說以較多的儲存空間換取較少的查詢時間,或是以較少的儲存的成本,但犧牲較多的查詢時間。這些作法都不是最好的,在硬體速度不斷進步情況下,應該可以利用更好的數學運算求取儲存成本與查詢時間的平衡點
● 軟體缺乏資料壓縮能力:有少數的軟體提供資料壓縮功能來降低儲存空間的使用量,不過相對於用戶查詢時的時間耗費,使用者並沒有佔到太大的便宜,這是一個治標不治本的方法,並沒有真正解決資料倉儲資料擴張問題
● 資料倉儲軟體本身的問題:軟體本身也是會有Bug的!有時一個儲存策略的選擇錯誤或是演算法有問題,就會讓資料以等比級數式的成長,但由於你是使用者而不是研發人員,這種錯誤通常是很難被發現的
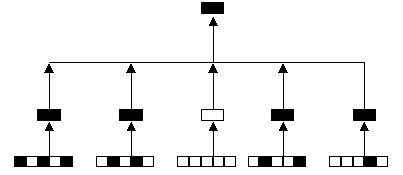
很明顯的,似乎沒有什麼技術性方法可以降低資料的擴張,既然如此我們就來看會擴張到什麼程度,以及資料稀疏對資料倉儲的影響。(圖二)是一個一維的OLAP分析個案,假設有25種商品銷售類別(你可以把這25個類別的基本資料視為是OLTP當初要轉入的資料),這些類別又分別屬於5大群組,在正常情況下,系統會產生5大群組的彙總資料,及所有的商品的銷售彙總,它將會使用31個空間(25+6),而資料的成長率則是1.24(31/25),如果把沒有存放資料的類別拿掉,則只使用13個空間(5+8),而資料成長率則是1.625。
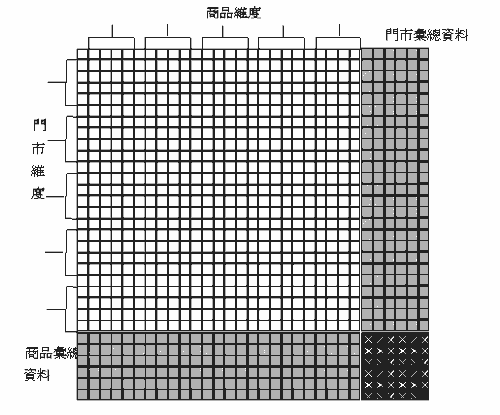
如果把圖二變為二維呢?假設是有25種類別的商品與25種類別的門市(這些類別的門市又分為5大群組)要進行門市的二維交叉分析,會產生多少資料?在(圖三)中充份的提供了答案。系統將會產生625(25x25)個基本的類別交叉分析資料空間,以及產生336個彙總式資料(27x27-625),資料的成長率將是(625+336)/625,也就是1.5376,如果把沒有存放資料的類別拿掉,會出現什麼情形?曾有人以電腦模擬做出下這樣的研究:
從這裡可以歸納出由RDB轉為MDDB時資料膨脹的一些因素:
● 維度與階層因素:假設RDB中只有一筆資料要轉入MDDB,在一維中商品有一個維度,25個基本類別、3個階層,總共使用了31個空間,可是多了一個門市維度,它也有25個基本類別、3個階層,卻使用了961個空間!比原先的一維狀況多使用930個空間。這種空間膨脹的問題將因為維度與階層的變多而大量擴張,並不會因為RDB資料的多寡而受影響;
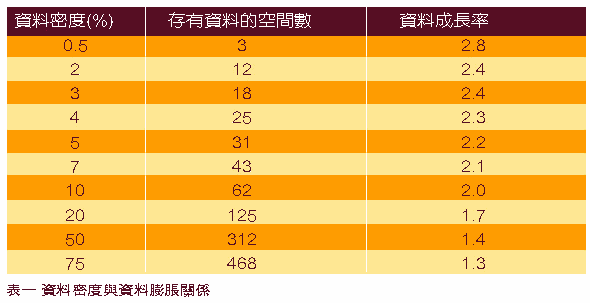
● 稀疏資料處理因素:從(表一)中可以很明顯的看出來,MDDB是否有稀疏資料的處理能力,也將會大大的影響資料膨脹的程度;
● 資料儲存的策略:是選擇ROLAP、MOLAP或HOLAP儲存資料倉儲資料,以及RDB原始資料是否被轉換並儲存於MDDB也都是影響資料膨脹的因素;
● 預儲的程度:是所有的各階層、各維度都要進行預算與預儲,或是某一個階層以上才進行預儲,例如依時間將資料分為週、月、季、年,選擇計算到週與選擇計算到年,所耗用的資料空間可能會有52倍的差距;
到目前為止,市面上的軟體還沒辦法很有效的控制資料擴張的問題,反到是從目標導向方式,回過頭來控制你可以使用的空間或是預儲的程度,如Microsoft SQL Server 7.0,是利用對預算與預儲程度,或是願意使用多少空間儲存資料,來控制資料空間的使用。
資料移轉問題
另一個在資料倉儲運作中非常重要的問題是:資料的移轉問題。在資料由RDB移到資料倉儲的多維式資料庫過程中必須注意到完整性與正確性,包括:
● 每日交易資料的移轉:一般業界對資料倉儲的應用很少會要求到資料具有即時性,大部份的情況只要做到每天晚上有批次可以將當日交易資料移轉過去就可以,不過在移轉的過程要注意時間控制,以零售業為例,晚上10點到次日凌晨3點通常是回收門市文字檔訂貨/銷售資料及轉換成資料庫格式的時間,如果在這一段時間進行資料移轉必須考慮資料鎖定、骯髒讀取(Dirty Read)、網路資料流量過大的問題,而如果在凌晨3點以後才開始進行資料移轉則可能會有時間不夠的困擾,再加上如果作業系統、交易系統每日有定時的備份、複製、鏡射,那麼可以用來移轉的時間就會非常少,因此如何在有效時間內把資料移轉過去要非常仔細的計算。
● 移轉的正確性:資訊界的名言「垃圾進,垃圾出」,在資料移轉的過程更要注意。資料倉儲的資料是由很多不同的交易系統所匯集而成,而每個交易系統本身就有一些一致性與完整性的問題,匯整成一個系統後這些問題同樣會出現,而且可能更嚴重。這些問題包括︰
1. 一致性與完整性問題(每個交易資料庫本身是否有資料衝突、資料重覆、參考完整性的問題,以及這些交易系統匯集成一個多維式資料庫時是否會有這些問題)。
2. 單位問題(同樣是金額的欄位,在A系統是以千元為單位,在B系統卻是以元為單位,在轉入過程一定要思考清楚應用何種單位,如用元是否會造成報表欄位過長,如用千元則要考慮500元以上和以下應如何四捨五入)。
3. 同義詞問題(ROC、R.O.C.、Republic OF China這三個都是同義字,但由於輸入方式不同卻變成三筆資料)。
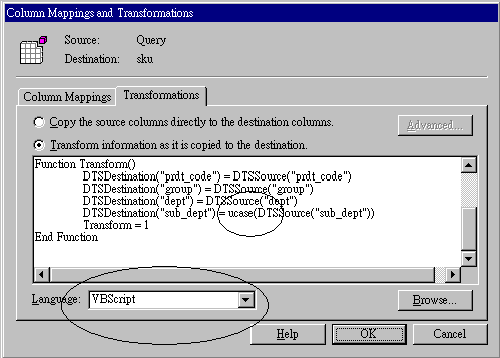
4. 技術問題(某些資料庫對特定字元有排斥作用,如SQL Server的字串內不可以有「 ‘ 」,當你輸入「He's a student」會被SQL Server認為是一個錯誤,要解決這個問題必須要另外用一段處理程式處理)(圖四)
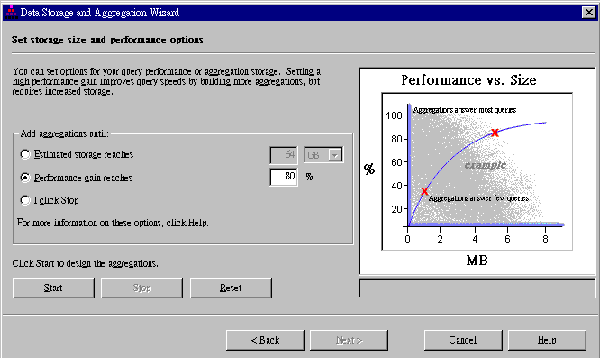
| 《圖四 SQL Server 7.0利用Storage與Performance控制資料庫的大小》 |
|
● 缺值的處理:只要有系統的地方大概就會碰到資料缺值的問題,可能是Null、空字串或0,在資料移轉的過程必須對這些記錄進行判別,依使用狀況將該記錄捨棄(但可能在計算筆數的時候少一筆)或保留(但在計算測量值總合的時候卻可能會造成困擾)。
Microsoft SQL Server 7.0的Data Transformation Services是這一版SQL Server最重要的工具之一,可以在資料庫移轉過程對要移轉的資料進行調整,包括資料內容的運算(大小寫、字串分解、加總)、資料過濾(只轉入符合條件的資料)及資料組合(從不同表格中抓取資料欄位再轉到SQL Server的同一個表格),這個功能比傳統Access的Import/Export、或Foxpro的Upsize有更強大的商業價值。(圖五)
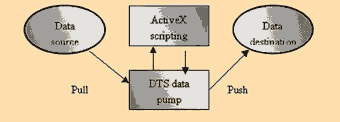
MS DTC基本上是經由OLE DB進行各種資料的轉入和轉出,而所有資料轉換過程中的定義則是都儲存於Microsoft Repository。它是利用拉與推(Pull and Push)的幫浦原理,從來源資料庫抓資料出來丟到資料幫浦(Data Pump),經由Microsoft ActiveX scripting function(Microsoft Visual Basic ,Scripting Edition、Jscript development software或PerlScript),進行資料複製、驗證和轉換,然後再傳給目的資料庫,目的資料庫可以是經由OLE DB或ODBC連接的資料庫,也可以是ASCII或HTML。這整個轉換的過程的歷史紀錄和每一個資料處理方式的定義都會被記錄下來,以讓用戶知道資料從何而來與將往何去,也可以做為開發人員稽核的依據。(圖六)
結論
由於有SQL Server之類的資料倉儲解決方案出現,使得中小企業有機會用極少的投資就享有以往大企業才能使用的資訊科技優勢,中小企業可以經由資料倉儲工具去分析各種資訊及發現未來趨勢。不過就如同導入其它系統一般,都會有一些風險存在的,資料倉儲觀念的導入除了要注意是否符合用戶需求外,還要注意資料膨脹及資料移轉問題,本文以SQL Server 7.0為例提供一些看法讓讀者了解這些問題的處裡方式,以做為未來導入資料倉儲的時的參考指引。
(網際先鋒2000.1月號68期)