在本篇文章中,筆者將介紹何謂網路資料探勘、並針對網路資料探勘系統的架構與規劃、網路資料探勘技術所遇到的瓶頸與挑戰,以及網路資料探勘技術未來的走向與趨勢做一個詳細的說明。
電子商務與網路資料探勘
由於網際網路(Internet)與全球資訊網(World Wide Web)的盛行,網路使用人口也急速地成長,並成為從事商業交易、行銷,以及廣告等商業行為的重要工具及媒介。許多原本不是在網路上的活動也藉由網路之便,迅速地在網路上走紅,電子商務(Electronic Commerce)就是一個很明顯的例子。
電子商務系統即所謂的 “網路商店”( Cyberstore)或 “線上購物”(On – Line Shopping)系統。它藉由網際網路的雙向溝通,使得企業可將產品、服務和廣告等訊息存放在企業所建置的網站上,讓消費者可藉由企業所建置的網站伺服器 (Web Server)獲得所需的資訊,同時也可在此網站上訂購商品或留置訊息。因此,電子商務系統提供了一種無國界、無時差的業務管道,也讓它在國際市場上佔有非常重要的商機。
然而,許多的電子商務網站僅是將公司與產品的簡介等作成單純的網頁,並以靜態的方式提供資訊服務,卻沒有考慮到顧客真正的興趣與喜好,也沒有與顧客間形成互動,以提供顧客真正感興趣的商品資訊,這跟一個顧客實際到一家商店購物的感覺是非常不同。
一個顧客實際到一家商店購物,店員會針對顧客的需求,來幫助顧客尋求或詳加解說商品。如果僅是提供靜態的服務,只可以說是達到詳加解說商品的目的而已,顧客仍需花費更多的時間和精力,去搜尋自己真正想要的商品。因此,了解您網路上的顧客是誰?他們都在您的網站上做什麼?就變成目前電子商務網站急需具備的基本功能。要做到這些事,則必須有賴於網路資料探勘的技術。
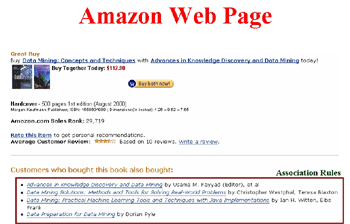
舉例來說,(圖一)是亞馬遜(Amazon)書店的購物畫面,在這個畫面中,一個顧客想購買兩本有關資料探勘的書。網頁除了呈現這兩本書的內容外,在網頁下方也有一個Also Bought的推薦,其目的就是藉由此種方式來達到書籍的交叉銷售(Cross – Sell)。而要達到此功能,則必須在顧客以往的網路交易記錄上,進行資料探勘中的關聯規則(Association Rule)技術運作。換句話說,我們可以利用資料探勘中的關聯規則技術來找出顧客購買網路產品之間的關聯性,並利用此關聯性來達成交叉銷售的目的。
一般來說,網路資料可細分成下列幾個部份:
- * 網頁本身的內容(Content of Web Pages)
- * 網頁本身的結構(Intrapage Structure of Web Pages):網頁本身的結構通常是以HTML或XML的方式來表達。
- * 網頁間的結構(Interpage Structure of Web Pages):網頁之間通常是以超連結 (Hyperlink)的方式來相互連接,形成網頁結構。
- * 使用者參與網路活動的記錄(U sage data that describe how web pages are accessed by visitors)
- * 使用者的個人資料(User Profile):使用者的個人資料通常包含使用者的背景資料(Demographic)、使用者的網站註冊資料(Registration Information),以及使用者在Cookies上的資料。
網路資料探勘技術就是植基在這些網路資料上,去發掘顧客的網路行為。
網路資料探勘的系統架構與規劃
目前市面上有許多網站分析的工具(Web Analysis Tools),如Web Trends (http://www.webtrends.com/)、Open Tracker(http://www.opentracker.net/),及Net Genesis(http://www.netgen.com/netgenesis/)等。然而這些網站分析工具大多集中在統計顧客在網站上的資訊,如那個網頁最受顧客的青睞,它的點選率(Page Hits)有多高、來瀏覽網站的顧客都是從那個地方連結過來、一星期中的網站每天的流量有多少等。這些資訊雖然重要,但對於我們要全面了解顧客而言,它們還是不夠。
同時,點選的次數並不代表造訪顧客數,點選次數多的網頁也不一定代表來瀏覽的顧客多(因為一個人可以點選多次),也不一定是熱門的網頁(因為網頁被點選多次有時是因為它在網站中的位置(Location),而不是它的內容(Content))。首頁(Homepage)就是一個最好的例子,在一個網站中,首頁通常被點選的次數是最多的,這是因為它是入口的網頁,而不是因為它的網頁內容。
通常,一個完整的網路資料探勘系統必需包含兩個部分:
- 1. 網路資料的收集(Web Access Data Collection)
- 2. 網路資料探勘的方法(Web Pattern Mining)
網路資料收集,在於強調收集顧客在網路上的一舉一動,並區分顧客。而網路資料探勘的方法則強調在伺服端所收集到的資料上,發掘出隱含在資料內的顧客行為。在網路資料的收集上,一般有下列兩種收集方式:
- 1. 在伺服端收集資料(Server – Based Data Collection)
- 2. 在客戶端收集資料(Client – Based Data Collection)
由於伺服端在收集資料時,是收集所有人在網站上的行為,因此將來在這種資料上做探勘時,會發掘出大眾化的行為模式。例如可能會發掘出 “大多數的顧客通常會先瀏覽網頁D,然後瀏覽網頁A和購買產品P,最後會到網頁C” 等大眾化行為。
而客戶端在收集資料,由於是收集某個人在網站上的行為,因此將來在這種資料上做探勘時,會發掘出個人化的行為模式。例如可能會發掘出 “顧客T在這個網站上,通常會先瀏覽政治性的網頁,然後再到討論區” 等個人化行為。
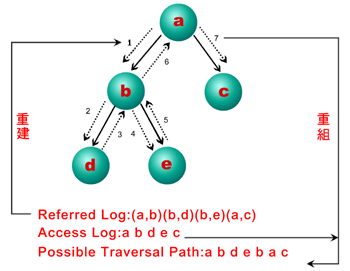
伺服端的資料收集通常是藉由整合網站伺服器(WWW Server)中的Access Log及Referred Log獲得。Access Log中記載使用者在什麼時間(例如:12/Apr/ 1999:11:31:40),從那個Domain Name(例如:flea.cs.kobe-u.ac.jp)或IP(例如:163.221.174.24)連線到這個網站,以及存取什麼資料(例如:GET/dasfaa99/New.gif)。(圖二)便是Access Log的一個範例。
在Referred Log中,會以配對的方式記載使用者目前的網頁及即將存取的網頁。例如假設目前的網頁為A.htm,而使用者即將存取B.htm,則(A.htm、B.htm)這個配對就會被存進Referred Log中。
藉由整合Access Log和Referred Log的動作中,網管可以得到使用者完整的瀏覽網站的資料。(圖三)為一個使用者瀏覽網站的例子,在這個例子中,使用者先瀏覽a、b、d,然後回到b、e,然後再回到b、a,最後到c。Access Log和Referred Log的內容也分別在(圖三)中呈現。網管可利用Referred Log重建網站架構,再搭配Access Log將使用者可能的瀏覽路徑(Possible Traversal Path)重組出來。
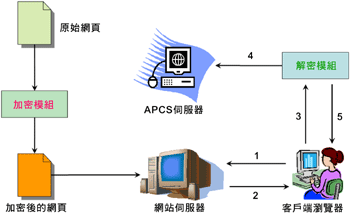
客戶端的資料收集通常是先安裝一個客戶端的程式,然後再藉由這個程式在客戶端收集顧客資料並回傳到選定的資料庫中。國立台灣大學陳銘憲教授實驗室所發展出的Access Pattern Collection Server(APCS)系統即為這方面的代表。如(圖四)所示:
在(圖四)中,每一個原始網頁均在加密(Enciphering)後,才放置在網站伺服器中。當使用者從客戶端的瀏覽器(Web Browser)要求看某一個網頁時,網站伺服器便會將加密後的網頁下載至客戶端的瀏覽器中。此時,如果使用者沒有安裝客戶端的資料收集程式則會看到亂碼,網頁無法正常顯示,但如果有安裝,則此程式首先會至APCS伺服器記錄使用者存取那個網頁,然後再將加密後的網頁解密(Deciphering),最後再將解密後的網頁正常顯示在客戶端的瀏覽器上。
基於這些收集到的資料,網路資料探勘就是要將隱含在這些資料中的顧客行為發掘出來。一般常見的網路使用探勘方法有下列幾種:
- * 關聯規則(Association Rule)
- * 路徑瀏覽型樣(Path Traversal Pattern)
- * 網頁瀏覽型樣(Web Traversal Pattern)
- * 網路交易型樣(Web Transaction Pattern)
在電子商務的網路環境中,顧客購買商品間之關聯規則(Association Rule)的找尋是一個重要的商機。所謂的關聯規則,如下所例:
- * 噴墨印表機,墨水匣 =>印表紙(可信度=80%,支持度=30%)
其意義為:在所有的交易中,有30%的交易會同時購買噴墨印表機,墨水匣與印表紙這三項產品;而在所有購買噴墨印表機與墨水匣的交易中,有80%的機率會一起購買印表紙。當我們提供這樣的資訊給網站的經營者時,他們便可依此資訊來做出新的決策,以增加其交叉銷售的機會。
探勘路徑瀏覽型樣(Path Traversal Patterns))則是想要在電子商務的網路環境中,尋找出大多數顧客的瀏覽行為。當我們了解大多數使用者在網路上的瀏覽行為後,我們便可以提供這些資訊給網站設計者,以改善網站的設計。舉例來說,假設我們探勘出大多數顧客經常瀏覽的路徑為<A、B、A、C>。這代表大多數的使用者瀏覽網頁A後,會去瀏覽網頁B,然後回到網頁A,最後會去瀏覽網頁C。
在這樣的探勘結果下,一條由網頁B直接到網頁C的連結則是有相當的必要性。同時,這項技術也可用來改善Proxy Server在預取(Prefetching)及快取(Caching)上的效率。舉例來說,假設我們探勘出大多數顧客經常瀏覽的路徑為<A、B、C>,則在使用者瀏覽網頁A的同時,Proxy Server便立即利用此項訊息將網頁B與C預取進來,並放置在使用者的快取中,以便使用者繼續瀏覽網頁B或C時,能立即獲得所需的網頁、提昇網站的效率。
然而,傳統探勘路徑瀏覽型樣的演算法都有一個限制:他們只能發掘出簡單的路徑瀏覽型樣(網頁不能重複的出現在同一個路徑瀏覽的型樣之中)。不過在電子商務的網站中,非簡單瀏覽序列則更能發掘出顧客的心理狀況,且能提供更多的資訊。因此,網頁瀏覽型樣(Web Traversal Pattern)的方法也陸續在網路資料探勘領域中被提出,並用來產生非簡單的瀏覽序列。
近來,網站經營者感到興趣的是顧客在購買相關產品時,是依照何種的瀏覽路徑來完成購買這些商品的程序;而只靠單純的商品間探勘關聯規則,及顧客瀏覽型樣並無法滿足網站經營者在這方面的需求。為了克服只單純的探勘關聯規則或瀏覽型樣所帶來資訊不足的缺點,網路交易型樣(Web Transaction Pattern)的研究也逐漸受到重視。
網路交易型樣技術又稱為網頁瀏覽型樣之關聯規則技術,它可同時發掘使用者在瀏覽網站與購買商品之間的關聯性。舉例來說,(表一)是記錄使用者瀏覽網站與購買商品的資料庫;(表二)是利用網路交易型樣技術列出部分的探勘結果。其中 <ACAE:C{2}=> E{3}>是表二中的一個網路交易型樣,它的意義是在33%的交易中,顧客會先瀏覽A、C(購買產品2),然後再回到A,最後到E(購買產品3)。而當顧客已瀏覽A、C、A並在C購買產品2之後,100%的顧客會瀏覽E,且同時購買產品3。
表一
|
交易編號 |
瀏覽路徑 |
購買商品 |
| 1 |
BECAFC |
F{1} |
| 2 |
DBACAE
|
C{2}, E{3} |
| 3 |
BDAE
|
|
| 4 |
BDECAFC |
F{1} |
| 5 |
BACAE |
C{2}, E{3} |
| 6 |
DAC |
C{2} |
|
網路交易型樣 |
支持度 |
信賴度 |
| <BECAF: F{4}> |
2/6 |
2/2 |
| <BACAE:
C{2} ==> E{3}> |
2/6
|
2/2 |
| <ACAE: C{2}
==> E{3}> |
2/6
|
2/2 |
| <ECAF:
F{4}> |
2/6 |
2/2 |
| <BAE: E{3}> |
2/6 |
2/5 |
| <CAF:
F{4}> |
2/6 |
2/2 |
| <DAC: C{2}> |
2/6 |
2/4 |
| <CAE:
C{2} ==> E{3}> |
2/6 |
2/2 |
|
<AC: C{2}> |
3/6 |
3/6 |
由(表二)可以看出,網路交易型樣技術在結合網頁瀏覽型樣(因為它探勘的結果允許網頁可重覆出現 – 非簡單瀏覽序列)及關連規則的分析後,可以發掘使用者在瀏覽網站與購買商品之間的關聯性。
網路資料探勘技術所遇到的瓶頸與挑戰
在伺服端的資料收集上,我們通常會遇到兩個問題:
- 1. 代理伺服器的使用(The Use of Proxy Server)
- 2. 快取的效應(The Effect of Caching)
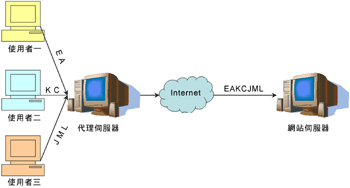
代理伺服器(Proxy Server)的使用會造成網站伺服器誤記要求網頁的來源為代理伺服器;以(圖五)為例,由於三個使用者(一個要求網頁E和A、一個要求網頁K和C、一個則要求網頁J、M和L)都聯結到相同的代理伺服器,並透過代理伺服器聯結到網站伺服器,所以網站伺服器會記錄下來這台代理伺服所器要求的網頁E、A、K、C、J、M和L;因此記錄會發生錯誤,而其探勘的結果也會不正確。快取的效應則會造成部分所要求的網頁,直接從使用者端的快取中取出,而網站伺服器的記錄則會呈現斷斷續續的現象,造成無法藉由Access Log及Referred Log推斷出使用者的真正的瀏覽路徑。
不過由於網路技術的高速發展,就目前而言,上述部分的問題已獲得解決。舉例來說,我們可以使用較先進的網站伺服器(HTTPd的通訊協定要在1.1版之後),即可記錄到代理伺服器背後的來源電腦,以解決網站伺服器記錄錯誤的問題,或是利用有支援Section ID的程式語言如Active Server Pages(ASP)也可解決上述部分的問題。基本上一個Section ID代表一個瀏覽器,並不會受到代理伺服器的影響。
然而還是有些問題暫時是無法解決的,例如當多人共用一台機器時,我們便無法區分這些使用者。另外,當一個人使用多台來源機器時,我們也無法區分這是否為同一個使用者;同時,網站伺服器也只能記錄使用者在自己伺服器中的行為,當使用者離開目前的伺服器而轉移到別的伺服器時,我們便記錄不到使用者在其他伺服器的行動,而這些問題還需更先進網路技術的支援才能解決。
另一方面,快取(Cache)的效應已能透過在網頁中加註過期標籤的方式,解決網站伺服器記錄不完整的問題。我們可以在網頁的<head>及</head>間加入以下的標籤:
<meta http-equiv=="Pragma" content="no-cache">
<meta http-equiv=="Expires" content="Tue, 01 Jan 1980 1:00:00 GMT">
如此一來,使用者在每次要求網頁時,一定會跟網站伺服器要,而不會直接從使用者端的快取中取出。許多線上的系統也利用此種方式,保證不會讓使用者看到過期的資訊。例如,使用者絕對不會在中時電子報看到昨天的新聞,因為它們用的就是這個技巧。
客戶端的資料收集相對於伺服端的資料收集是相當準確且詳盡,它可以很容易的區分使用者,因為每個使用者都需經過註冊的手續才可使用此程式。它也可記錄到使用者在瀏覽器的所有行為,而不僅止於某台網站伺服器。
然而,它有一個嚴重的缺點就是使用者隱私權的問題。當要安裝一個程式時,使用者通常會裹足不前,因為害怕程式收集到非自己所能預期的資料,而這也是為什麼APCS系統要先將資料加密,以強迫使用者必需安裝程式,才能正常運作的原因。雖然伺服端的資料收集也有隱私權的問題;然而,使用者並不會感覺到,也不會有安裝軟體的動作;因此,情況較沒有那麼嚴重。
在網路資料探勘的技術上,就目前開發出的技術而言,需要再加速探勘所需的時間(目前的方法仍不夠快),以及再開發更多的方法(目前的方法仍不夠多),以快速地提供決策者更多的資訊與知識。
結語
了解一個顧客在網站上行為是十分重要,網路資料探勘(Web Mining)的技術提供了一個了解客戶的可能管道。利用網路資料探勘技術,我們可以重新規劃、組織網站,以方便顧客瀏覽網站;我們也可以利用它來增進網站的效能、決定廣告出現的位置,最重要的是它還能幫助我們增加商機。
在未來的走向上,於資料的收集的部分我們要密切注意新的網路技術。更先進的網路技術會使資料的收集更加容易與精準。目前網路資料探勘的方法,是朝向漸進式探勘(Incremental Mining)的方向來進行,在網路瀏覽的資料庫中,隨著時間的推進,資料量是會持續地擴增。相對於原始的資料量來說,其所增加的資料量可能根本微不足道,所以我們是否有必要為了這些小小的變動,再將全部的資料重新探勘一次呢?
不過我們若是不重新作探勘的動作,最後的分析結果就有可能會因此而產生誤差。所以在資料庫更新後,是絕對有必要重新作探勘,但又考慮其探勘時間的浪費,因此漸進式探勘的方法就十分重要了。漸進式探勘的主要精神為利用過去探勘的結果,並針對其新增的資料,進行更進一步的探勘動作,以增進其探勘的效率,至於要如何達成,則有賴專家學者作更進一步的研究了。
<作者為銘傳大學資訊工程學系副教授>
|
|
 |
遠距教學的生存和發展將取決於能否提供個性化的教學服務,Web
Mining技術使個性化的遠距教學成為可能。本文就Web Usage Mining技術在個性化遠距教學系統中的應用作了探討和研究。相關介紹請見「Web
Usage Mining在遠距教學中的應用」一文。 |
|
本文揭示了未來數位圖書館中圖書館員進行資訊服務的一種方式,敘述資料挖掘和WEB挖掘的基本原理和方法,並強調圖書館員應掌握資料挖掘這項新技術的必要性。你可在「資料挖掘
– 圖書館員應掌握的基本工具」一文中得到進一步的介紹。 |
|
目前許多電腦軟體結合了網路伺服器和資料庫所記錄的網站訪客上網資料或網站消費者的交易資料,提供「統計性質」的匯總報表,而網際探勘(Web
Mining)則是幫助經營者來進行決策性的判斷。在「網站經營利器」一文為你做了相關的評析。 |
|
|
 |