神經處理單元(NPU)的出現,對於機器學習領域產生了革命性的改變,它使得深度學習任務所需的複雜數學運算能夠高效執行。透過最佳化矩陣乘法和卷積運算,NPU將AI 模型大幅擴展到各種領域,從高階伺服器群到低階電池供電裝置皆適用。
微型機器學習(TinyML)專注於在資源受限的嵌入式裝置上實現機器學習演算法,它的興起進一步推展了AI 的界限。TinyML讓數十億的邊緣裝置具備 AI 能力,使它們能夠在本地即時處理資料並做出決策,而且無需依賴雲端連線或強大的運算資源。

| 圖一 : 神經處理單元(NPU)使得深度學習任務所需的複雜數學運算能夠高效執行。 |
|
以 NPU 為基礎並結合新興的微型機器學習領域,Ceva 推出Ceva-NeuPro-Nano。這款精巧高效的 NPU IP 是專為微型機器學習應用而精心設計,它能夠在效能與耗電效率之間取得完美的平衡。Ceva-NeuPro-Nano 經過最佳化的獨特架構,能夠從頭到尾完整執行微型機器學習應用,涵蓋資料擷取、特徵萃取到模型推論,使其成為資源受限、電池供電裝置的嵌入式系統,提供理想的AI本地解決方案。

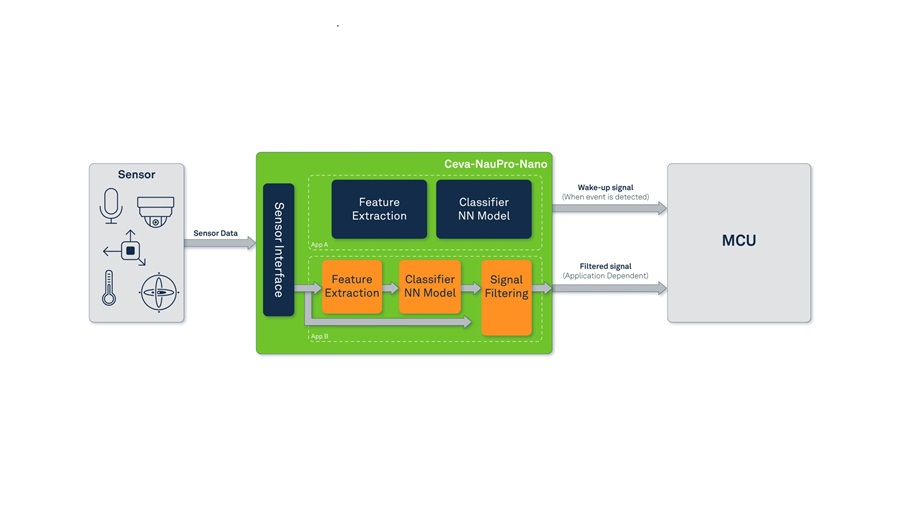
| 圖二 : Ceva-NeuPro-Nano 的設計願景源自於微型機器學習的使用者需求, (source:Ceva) |
|
設計理念
Ceva-NeuPro-Nano 的設計願景源自於微型機器學習的使用者需求,我們理解一個既強大又易用的解決方案,需要優先考慮軟體的易用性。除了專注於神經網路層級之外,必須能夠解決應用層面的挑戰。這種方法確保 Ceva-NeuPro-Nano 能夠高效且無縫地處理神經網路,同時應付控制任務與 DSP任務。
其目標是一個低耗電高效能處理嵌入式 AI 的最佳NPU。Ceva-NeuPro-Nano 尖端的硬體設計專為滿足微型機器學習應用所需的低功耗、高效率要求而量身打造,使其成為資源受限邊緣裝置的理想解決方案。
軟體優先
Ceva-NeuPro-Nano 全面的軟體生態系統支援兩大主要微型機器學習推論架構:
1.適用於微控制器的 TensorFlow Lite;2.MicroTVM。這確保了它能無縫整合到各種微型機器學習應用中。Ceva-NeuPro-Nano 與許多其他解決方案不同,它不是一個依賴主機微控制器(MCU)的AI加速器;它是一個完全可程式化的獨立處理器,同時具備卓越的神經網路(NN)和數位訊號處理(DSP)能力,使其具有前瞻性並能支援未來的任何網路層或運算子。
除了支援主要的微型機器學習架構以外,Ceva-NeuPro-Nano還配備全面的NN函式庫,適用於需要手動調整模型的情況,以及提供完整 DSP 功能的 DSP 函式庫。這些全面的函式庫提升Ceva-NeuPro-Nano 的適應性和多功能性,使得開發人員能夠輕鬆地開發各種獨特的應用需求。
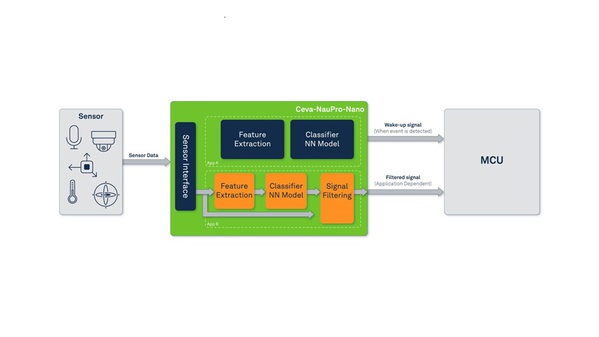
| 圖三 : Ceva-NeuPro-Nano 全面的軟體生態系統支援兩大主要微型機器學習推論架構 (source:Ceva) |
|
創新架構
Ceva-NeuPro-Nano 的架構引入了幾項創新特性,得以解決微型機器學習應用中的關鍵痛點。它能夠直接處理壓縮後的權重,無須對記憶體先進行權重解壓縮,可節省記憶體儲存權重的空間,使其成為記憶體受限微型機器學習裝置的理想選擇。先進的資料快取系統簡化硬體管理,並且提高整體效率,消除了直接記憶體存取(DMA)排程的複雜性。
Ceva-NeuPro-Nano 的硬體架構設計能夠處理非線性啟動函數,使其能支援多樣化的機器學習模型。它還整合了尖端的節能技術以確保高效率,使其非常適合對功耗敏感的邊緣裝置。透過硬體層級對稱和非對稱量化方案的支援,以及原生 4 位元資料類型的支援,Ceva-NeuPro-Nano 可以容納各種 TensorFlow 模型,進一步擴展其適應性,並實現更高效的資料處理和儲存。
MAC 大戰
許多神經網路處理器(NPU)製造商誇耀其設計中不斷增加的乘加(MAC)單元數量,暗示更多的 MAC 等同於更好的效能。然而,Ceva採取不同的方法來開發 Ceva-NeuPro-Nano,著重於 MAC 的使用效率,而非單純追求數量。
我們認知到,如果無法有效利用大量的 MAC 單元,那麼擁有這些單元並不一定能夠轉化為更好的效能。事實上,更高的 MAC 數量常常導致功耗增加,卻無法帶來相應的效能提升。Ceva-NeuPro-Nano NPU 有兩種變體:配備 32 個 8×8 MAC 的 Ceva-NPN32,以及配備 64 個 8×8 MAC 的 Ceva-NPN64。透過廣泛的實驗證明32-MAC 變體可以展現出與其他擁有 128 個 MAC 的解決方案相當的表現。這種卓越的效率是透過更高的 MAC 使用率達成的,而這得益於我們創新的設計和架構。
透過優先考慮 MAC 使用率而非單純的數量,Ceva-NeuPro-Nano 在保持較低功耗的同時提供了高效能。這種方法完全符合 TinyML 應用的需求,在這類應用中,電源效率至關重要。我們對效率的專注,證明了智慧設計和最佳化比投入MAC大戰更為重要。
橫跨3V的TinyML實用案例
在嚴謹的測試和分析中,我們比較各種 TinyML 模型在 NeuPro-Nano 和其他替代解決方案上的執行情況。結果凸顯了 NeuPro Nano 的驚人價值。它擁有 45% 更小的面積,提供 3 倍的能源效率,消耗高達 80% 更少的記憶體,並為 TinyML 網路提供高達 10 倍的改進。
我們透過專注於橫跨三大主軸(3 個 V)的實際 TinyML 應用案例,達成出色的效能和效率指標:
‧ 視覺(Vision):對於視覺應用,我們認識到輕量級電腦視覺任務(例如人臉偵測、特徵點偵測、物體偵測和圖像分類)在讓穿戴式裝置和物聯網裝置與環境互動和理解方面扮演重要的角色。我們考慮了一些強健、經產業驗證的神經網路設計,例如 EfficientNet、MobileNet、Squeezenet 和 tiny YOLO,這些網路能處理主要的輕量級電腦視覺任務。這確保了 Ceva-NeuPro-Nano 能夠優雅且高效地處理 CNN、深度可分離卷積和其他層。
‧ 振動(Vibration):對於振動應用,基於 Ceva 在 IMU 硬體、軟體和應用開發方面的獨特經驗,專注於人類活動識別和異常偵測等任務,這些在穿戴科技和工業應用中分別扮演關鍵的角色。
‧ 語音(Voice):對於語音應用,這是人機互動的下一步,基於自身在語音感測應用開發(例如用於關鍵字辨識、降噪和語音識別)方面的豐富經驗,以及我們對該領域的深入了解。考慮到從 RNN 和 CNN 到微型 Transformer 等多樣化的網路設計,確保NeuPro Nano 的設計能夠精通這些所有網路。
在整合這三個 V 時,我們認識到神經網路基礎應用中一個經常被忽視的部分 – 特徵擷取的重要性,這促使我們將強大的控制和 DSP 功能整合到 Ceva-NeuPro-Nano 的設計中。
結論
Ceva-NeuPro-Nano獨特的架構、高效的 MAC 利用率,以及全面支持的軟體生態系統,使其成為多功能且強大的解決方案;其設計理念聚焦於實際案例和應用層級的挑戰,確保它能高效且無縫地處理廣泛的任務。憑藉其突破性的效能、效率和適應性,Ceva-NeuPro-Nano 將徹底改變 TinyML 領域,為數十億資源受限的裝置帶來機器學習的力量。
Ceva-NeuPro-Nano 加入Ceva-NeuPro 系列神經網路處理器家族,並且擴展可以處理的邊緣 AI 工作負載範圍,從 TinyML 應用到大規模生成式 AI 模型。
(本文作者Ido Gus為CEVA感測器和音訊事業部深度學習資深團隊領導)